
TL;DR
Gretta is an AI compliance testing agent that replaces weeks of manual review with an automated sheet that pulls interactions, applies regulatory context across BSA/AML, UDAAP, Reg E, and Reg Z, flags defects, and queues remediation. Two weeks of work in an hour.
Why now
Over the last year working with fast-growing fintechs and public financial services companies, a recurring theme began to appear. Teams were hacking our QA system to run compliance testing, pulling interactions manually, scoring them against spreadsheet templates, logging findings one row at a time. They were making it work. But the tool was never built for this.
That told us something important.
The problem they were solving for is one of the most under-resourced in financial services. Compliance testing is not optional. It is a regulatory requirement. Examiners from the CFPB, OCC, and FDIC expect evidence that your institution is regularly testing the controls you said you would maintain across every product line, every channel, and every customer-facing workflow. If you cannot produce that evidence, you are exposed. And for most teams, producing that evidence means doing it by hand.
data samples per control
Each month spent testing
The process today
Here is what that looks like in practice.
Once a year, key controls are established around the risks the compliance team cares about. These controls map to specific regulations. BSA/AML flags around transaction monitoring and SAR filing obligations. UDAAP controls focused on Sales and Customer service. Reg E requirements around error resolution and dispute handling timelines. Reg Z disclosures in lending and credit workflows. Each control gets a template. Each template lives in a sheet. And then the testing begins.
Throughout the year, compliance teams run tests monthly, quarterly, or annually depending on the control. For each test, analysts pull a predefined template and evaluate it against live interactions: disputes, sales calls, customer service conversations, lending decisions, marketing materials, and fraud cases.
Each control typically requires 50 samples. Higher-risk areas require 100+ samples. For every sample, a reviewer pulls the interaction, reads or listens through it, compares it against the requirement, records a pass or fail, documents the finding, and moves to the next case with each review taking between 30 minutes and 1 hour.Most compliance teams we spoke with spend 30 to 50 hours per analyst each month just on testing. Some spend more.
And that is just the scoring.
Before a single finding gets logged, a reviewer has to locate the interaction in one system, pull the customer record from another, cross-reference the product terms from a third, check whether a similar issue was flagged in a prior testing cycle, and then manually calculate whether the defect rate crosses a threshold that requires escalation. Every step is a context switch. Every context switch is time. And at the end of it all, everything gets typed into a spreadsheet that will sit in a shared drive until the next examiner asks for it.
That is not a workflow problem. That is a structural problem. And it gets worse as your product surface area grows, as you add new customer segments, as you move into new states or new regulatory jurisdictions, as you hire AI agents to handle onboarding or servicing and suddenly have to monitor those too.
Nobody has built the right tool for this. Until now.
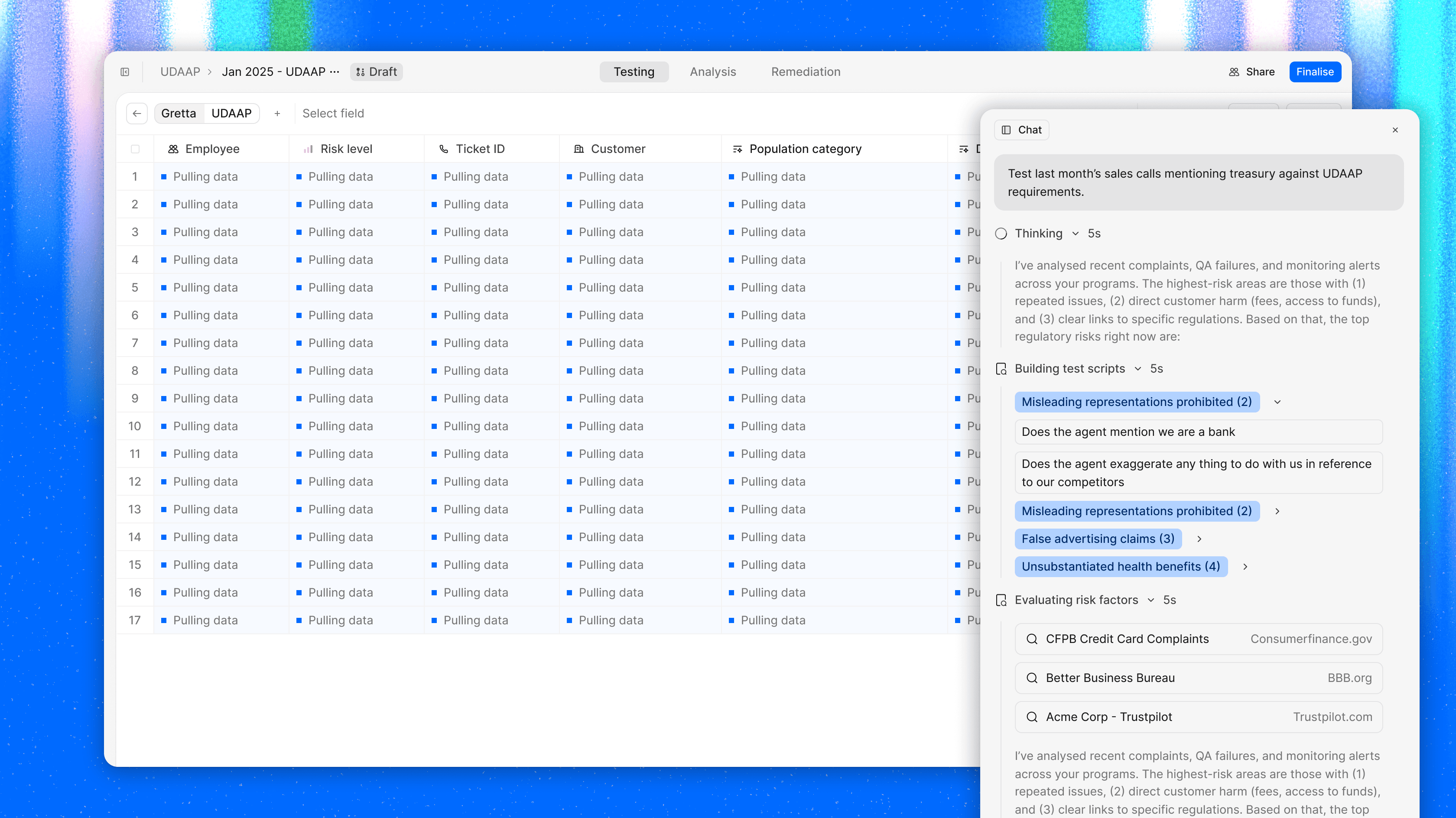
How Gretta works
Think of Gretta as a sheet, except every column has multiple AI agents built in. You bring your test scripts. We do the rest.
Each row pulls the interaction directly from your source systems, your CRM, your servicing platform, your call recordings, your chat logs, your dispute queue. No manual retrieval. No toggling between tabs. The interaction is there, in context, ready to be reviewed.
Each cell reads the relevant regulatory context in real time. What does BSA/AML require in this scenario? Is there a structuring pattern worth flagging, is the SAR threshold being approached, is the customer profile consistent with the activity? Where does UDAAP exposure live in this sales conversation? Was the product described accurately, were fees disclosed clearly, was there any language a regulator could characterize as deceptive or abusive? What does Reg E demand here? Was the dispute acknowledged within three business days, was provisional credit applied correctly, was error resolution completed within the required window? What does Reg Z require in this lending interaction? Were APR disclosures accurate, were payment terms presented clearly, was the right model form used?
Gretta knows the regulatory context because we built it into her. She does not just pattern match. She reasons against the actual requirements.
Each finding is then cross-referenced against your historical testing data. If a defect appears in one interaction, Gretta flags it. If the same defect has appeared in three of the last five testing cycles, Gretta surfaces that pattern and escalates the finding accordingly. Examiners do not just want to know that you found a problem. They want to know that you found it, understood it, tracked it over time, and fixed it. Gretta builds that record automatically.
And then she queues remediation. Not a note that says needs follow-up. A structured remediation workflow, what the defect was, which regulation it implicates, what the recommended corrective action is, who owns it, and what the deadline is. Your team inherits a workpaper, not a to-do list.
That is what regulatory-grade evidence means. Not a yes or a no. A finding with a citation, a defect rate, a trend line, a remediation recommendation, and an audit trail that holds up when an examiner walks through the door.
We turn a two-week testing process into an hour.
That is not a rounding estimate. Teams running 200-sample tests across four or five control areas, work that would previously consume two reviewers for the better part of two weeks, are completing the same scope in a single session. The time savings compound as you add controls, add products, and grow your team without growing your compliance headcount.
This is just the beginning of where we are going. Gretta will expand to cover additional regulations and additional interaction types. She will evolve into a living compliance record, not a snapshot you produce for examiners, but a continuous, always-current view of where your program stands.
If you are a compliance lead who wants to see this live, book a demo below.